
Exzerpt aus: Mandl, Peter, Andreas Bakomenko, und Johannes Weiß. Grundkurs Datenkommunikation: TCP/IP-basierte Kommunikation: Grundlagen, Konzepte und Standards. 1. Aufl. Studium. Wiesbaden: Vieweg + Teubner, 2008.
Das ISO/OSI-Referenzmodell
Die gesamte Funktionalität, die hinter der Rechnerkommunikation steckt, ist zu komplex, um ohne weitere Strukturierung verständlich zu sein. Im Rahmen der Standardisierungsbemühungen der ISO hat man sich daher gemäß dem Konzept der virtuellen Maschinen mehrere Schichten ausgedacht, um die Materie etwas übersichtlicher zu beschreiben. Das ISO/OSI-Referenzmodell (kurz: OSI-Modell) teilt die gesamte Funktionalität in sieben Schichten ein, wobei jede Schicht der darüberliegenden Schicht Dienste für die Kommunikation bereitstellt. Die unterste Schicht beschreibt die physikalischen Eigenschaften der Kommunikation und darüber liegen Schichten, die je nach Netzwerk teilweise in Hardware und teilweise in Software implementiert sind.
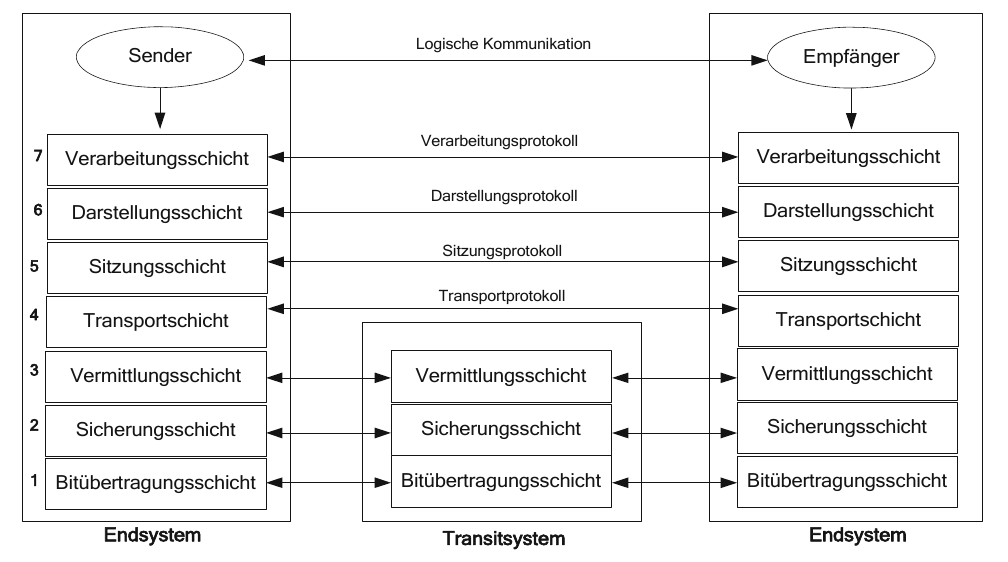
Die Schichten einer Ebene, die in verschiedenen Rechnersystemen (auch offene Systeme genannt) instanziert werden, kommunizieren horizontal miteinander über Protokolle. Jede Schicht innerhalb eines offenen Systems stellt der nächst höheren in vertikaler Richtung Dienste zur Verfügung. Das Konzept der virtuellen Maschine findet hier insofern Anwendung, als keine Schicht die Implementierungsdetails der darunterliegenden Schicht kennt und eine Schicht n immer nur die Dienste der Schicht n-1 verwendet.
...
Die einzelnen Schichten haben im ISO/OSI-Referenzmodell folgende Aufgaben:
- Die Bitübertragungsschicht (Schicht 1) ist die unterste Schicht und stellt eine physikalische Verbindung bereit. Hier werden die elektrischen und mechanischen Parameter festgelegt. U. a. wird in dieser Schicht spezifiziert, welcher elektrischen Größe ein Bit mit Wert 0 oder 1 entspricht. Hier werden nur Bits bzw. Bitgruppen ausgetauscht.
- Die Sicherungsschicht (Schicht 2) sorgt dafür, dass ein Bitstrom einer logischen Nachrichteneinheit zugeordnet ist. Hier wird eine Fehlererkennung und -korrektur für eine Ende-zu-Ende-Beziehung zwischen zwei Endsystemen bzw. Transitsystemen unterstützt.
- Die Netzwerk- oder Vermittlungsschicht (Schicht 3) hat die Aufgabe Verbindungen zwischen zwei Knoten ggf. über mehrere Rechnerknoten hinweg zu ermöglichen. Auch die Suche nach einem günstigen Pfad zwischen zwei Endsystemen wird hier durchgeführt (Wegewahl, Routing).
- Die Transportschicht (Schicht 4) sorgt für eine Ende-zu-Ende-Beziehung zwischen zwei Kommunikationsprozessen und stellt einen Transportdienst für die höheren Anwendungsschichten bereit. Die Schichten eins bis vier bezeichnet man zusammen auch als das Transportsystem.
- Die Sitzungsschicht (Schicht 5) stellt eine Sitzung (Session) zwischen zwei Kommunikationsprozessen her und regelt den Dialogablauf der Kommunikation.
- Die Darstellungsschicht (Schicht 6) ist im Wesentlichen für die Bereitstellung einer einheitlichen Transfersyntax zuständig. Dies ist deshalb wichtig, da nicht alle Rechnersysteme gleichartige Darstellungen für Daten verwenden. Manche nutzen z. B. den EBCDIC - andere den ASCII-Code und wieder andere den Unicode. Auch die Byte-Anordnung bei der Integer-Darstellung (Little Endian und Big Endian Format) kann durchaus variieren. Unterschiedliche lokale Syntaxen werden in dieser Schicht in eine einheitliche, für alle Rechnersysteme verständliche Syntax, die Transfersyntax, übertragen.
- Die Verarbeitungs- oder Anwendungsschicht (Schicht 7) enthält schließlich Protokolle, die eine gewisse Anwendungsfunktionalität wie Filetransfer oder E-Mail bereitstellen. Die eigentliche Anwendung zählt nicht zu dieser Schicht. Hier sind viele verschiedene Protokolle angesiedelt.
- Für jede Schicht gibt es im Modell mehrere Protokollspezifikationen für unterschiedliche Protokolle. In der Schicht 4 gibt es z. B. verschiedene Transportprotokolle mit unterschiedlicher Zuverlässigkeit. Grob kann man auch festhalten: Die Schicht 2 dient der Verbindung zwischen zwei Rechnern (Endsystemen oder Zwischenknoten), sorgt sich also um eine Ende-zu-Ende-Verbindung zwischen zwei Rechnern. Die Schicht 3 unterstützt Verbindungen im Netzwerk (mit Zwischenknoten), also Ende-zu-Ende-Verbindungen zwischen zwei Rechnern (Endsysteme) über ein Netz. Die Schicht 4 kümmert sich um eine Ende-zu-Ende-Kommunikation zwischen zwei Prozessen auf einem oder unterschiedlichen Rechnern.
S.2ff
Das TCP/IP-Referenzmodell
Das von der Internet-Gemeinde entwickelte TCP/IP-Referenzmodell (vgl. Abbildung 1-6) ist heute der Defacto-Standard in der Rechnerkommunikation. Es hat vier Schichten, wobei die Schicht 3 (Internet-Schicht) und die Schicht 4 die tragenden Schichten sind. In der Schicht 3 wird neben einigen Steuerungs- und Adressierungsprotokollen (ARP, ICMP)6 im Wesentlichen das Protokoll IP (Internet Protocol) benutzt. In Schicht 4 gibt es zwei Standardprotokolle. Das mächtigere, verbindungsorientierte TCP (Transmission Control Protocol) und das leichtgewichtige, verbindungslose UDP (User Datagram Protocol). TCP gab dem Referenzmodell seinen Namen.

Im Gegensatz zum OSI-Modell wird im TCP/IP-Modell nicht so streng zwischen Protokollen und Diensten unterschieden. Die Schichten 5 und 6 sind im Gegensatz zum OSI-Modell leer. Diese Funktionalität ist der Anwendungsschicht vorbehalten, d.h. die Verwaltung evtl. erforderlicher Sessions und die Darstellung der Nachrichten in einem für alle Beteiligten verständlichen Format muss die Anwendung selbst lösen. Kritiker des OSI-Modells sind der Meinung, dass gerade die Funktionalität dieser beiden Schichten sehr protokollspezifisch ist. Es gibt Protokolle, die brauchen hier gar keine Funktionalität und andere, die hier sehr viel tun müssen. Über die unteren Schichten ist man sich prinzipiell einig. Alle Datenkommunikationsspezialisten sehen die Notwendigkeit für ein Transportsystem, wenn auch die Funktionalität je nach Protokolltyp hier sehr unterschiedlich sein kann. Beispielsweise gibt es verbindungsorientierte (wie TCP) und verbindungslose (wie UDP) Protokolle mit recht unterschiedlichen Anforderungen.
S. 9f
Electronic Mail (S.
Ein weiterer, heute im Internet weit verbreiteter Dienst ist der E-Mail-Dienst zum Austausch von elektronischen Nachrichten (Electronic Mails). Auch hier handelt es sich um eine Client-/Serveranwendung. Ein Benutzer verwendet einen E-Mail-Client, Mail User Agent (MUA) genannt, um E-Mails zu senden und zu empfangen und das Weiterreichen der E-Mails wird über E-Mail-Gateways abgewickelt. Jedem Benutzer, der E-Mails senden und empfangen möchte wird eine elektronische Mailbox mit einer eindeutigen E-Mail-Adresse (z. B. mandl@cs.fhm.edu) in einem E-Mail-Gateway zugeordnet. Die Mailboxen werden üblicherweise in den E-Mail- Gateways von Internet-Providern verwaltet. Die E-Mail-Gateways sind Serverrechner mit speziellen Softwarebausteinen für die Mail-Abwicklung. Sie haben in der Regel eine Doppelrolle. Zum einen nehmen sie Nachrichten von den MUAs entgegen. Diese Aufgabe wird als Mail Submission Agent (MSA) bezeichnet. Zum anderen leiten sie Nachrichten (E-Mails) für den Transport bis zum adressierten Empfänger in der Rolle von sog. Mail Transfer Agents (MTA) an andere E-Mail-Gateways weiter.

S.263
Web-Server
Ein Web-Server wartet auf ankommende Verbindungsaufbauwünsche standardmäßig auf TCP-Port 80, indem er die Socket-Funktion listen aufruft. Ein klassischer TCP-Verbindungsaufbauwunsch wird entgegengenommen. Steht die Verbindung, wird vom Web-Browser ein HTTP-Request erzeugt, der vom Web-Server empfangen und üblicherweise in einem eigenen Thread oder Prozess bearbeitet wird. Das gewünschte Dokument wird lokalisiert (wir nehmen hier die Adressierung einer statischen Web-Seite an, wozu im konfigurierten Root-Verzeichnis des Web-Servers gesucht wird.

Ein Web-Server (bei Apache auch als httpd-Hintergrundprozess ablaufend) enthält im Allgemeinen neben einer Steuerungskomponente eine Komponente zur Dokumentenverwaltung, evtl. eine Engine für die Servlet-/JSP-Bearbeitung, ASP-Bearbeitung, PHP-Bearbeitung und einiges mehr15 (vgl. Abbildung 6-13). Bei Java-lastigen Web-Servern ist auch eine JVM im Spiel. Die Server erzeugen für die Bearbeitung bestimmter Anfragen auch noch zusätzliche Prozesse. Insbesondere bei der relativ alten serverseitigen Programmiertechnik CGI 16 wird für jede Anfrage ein eigener Sohnprozess zur Bearbeitung erzeugt.
(S. 244)